
{kind=link}
Groq’s LPU Inference Engine, a devoted Language Processing Unit, has set a brand new document in processing effectivity for giant language fashions.
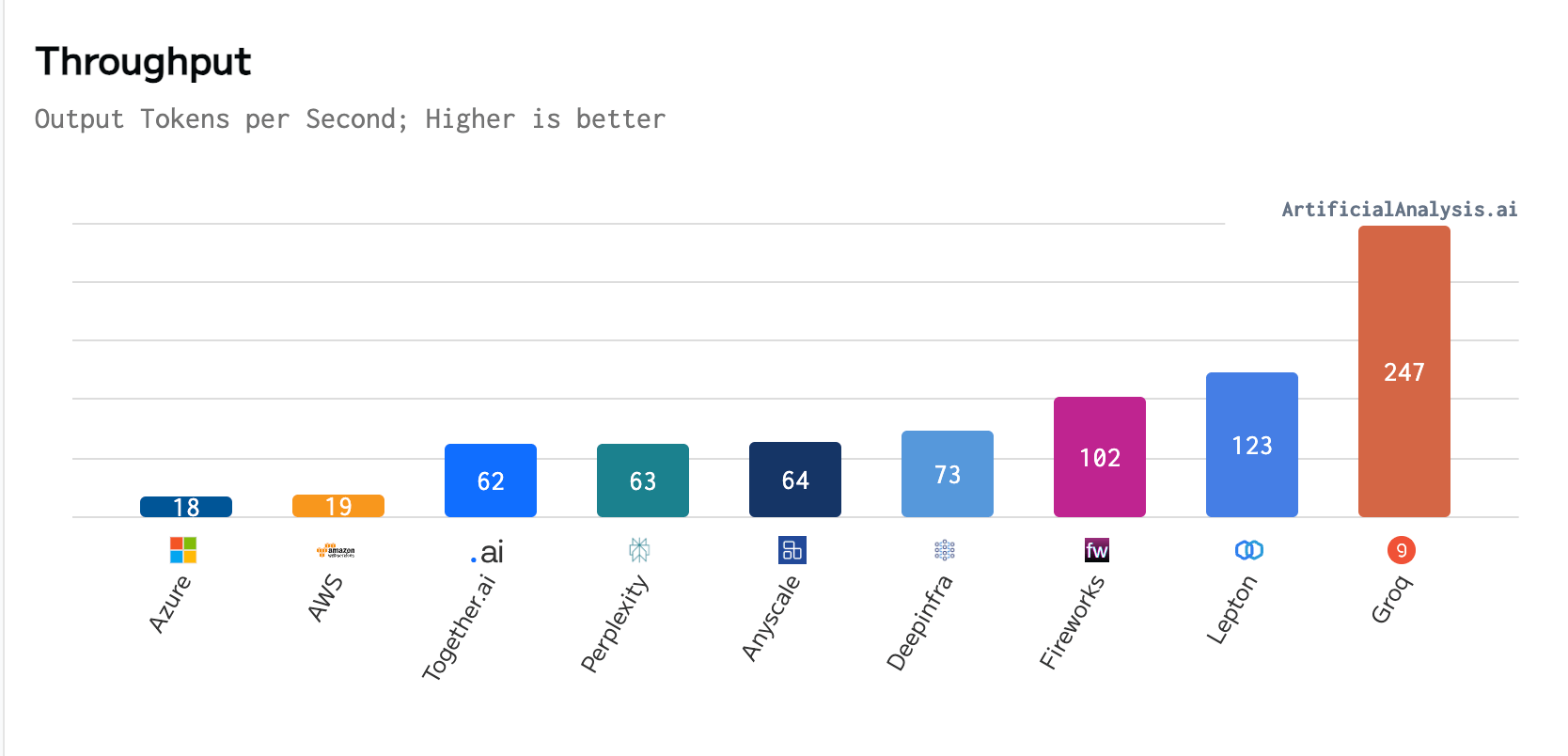
In a latest benchmark performed by ArtificialAnalysis.ai, Groq outperformed eight different individuals throughout a number of key efficiency indicators, together with latency vs. throughput and whole response time. Groq’s web site states that the LPU’s distinctive efficiency, significantly with Meta AI’s Llama 2-70b mannequin, meant “axes needed to be prolonged to plot Groq on the latency vs. throughput chart.”
Per ArtificialAnalysis.ai, the Groq LPU achieved a throughput of 241 tokens per second, considerably surpassing the capabilities of different internet hosting suppliers. This stage of efficiency is double the pace of competing options and doubtlessly opens up new potentialities for giant language fashions throughout varied domains. Groq’s inside benchmarks additional emphasised this achievement, claiming to achieve 300 tokens per second, a pace that legacy options and incumbent suppliers have but to return near.
The GroqCard™ Accelerator, priced at $19,948 and available to shoppers, lies on the coronary heart of this innovation. Technically, it boasts as much as 750 TOPs (INT8) and 188 TFLOPs (FP16 @900 MHz) in efficiency, alongside 230 MB SRAM per chip and as much as 80 TB/s on-die reminiscence bandwidth, outperforming conventional CPU and GPU setups, particularly in LLM duties. This efficiency leap is attributed to the LPU’s means to considerably scale back computation time per phrase and alleviate exterior reminiscence bottlenecks, thereby enabling sooner textual content sequence technology.

Evaluating the Groq LPU card to NVIDIA’s flagship A100 GPU of comparable price, the Groq card is superior in duties the place pace and effectivity in processing giant volumes of less complicated knowledge (INT8) are essential, even when the A100 makes use of superior methods to spice up its efficiency. Nonetheless, when dealing with extra advanced knowledge processing duties (FP16), which require better precision, the Groq LPU doesn’t attain the efficiency ranges of the A100.
Basically, each elements excel in several points of AI and ML computations, with the Groq LPU card being exceptionally aggressive in operating LLMS at pace whereas the A100 leads elsewhere. Groq is positioning the LPU as a software for operating LLMs slightly than uncooked compute or fine-tuning fashions.
Querying Groq’s Mixtral 8x7b mannequin on its web site resulted within the following response, which was processed at 420 tokens per second;
“Groq is a robust software for operating machine studying fashions, significantly in manufacturing environments. Whereas it will not be your best option for mannequin tuning or coaching, it excels at executing pre-trained fashions with excessive efficiency and low latency.”
A direct comparability of reminiscence bandwidth is much less easy because of the Groq LPU’s deal with on-die reminiscence bandwidth, considerably benefiting AI workloads by lowering latency and rising knowledge switch charges throughout the chip.
Evolution of pc elements for AI and machine studying
The introduction of the Language Processing Unit by Groq could possibly be a milestone within the evolution of computing {hardware}. Conventional PC elements—CPU, GPU, HDD, and RAM—have remained comparatively unchanged of their primary kind for the reason that introduction of GPUs as distinct from built-in graphics. The LPU introduces a specialised method targeted on optimizing the processing capabilities of LLMs, which might grow to be more and more advantageous to run on native units. Whereas providers like ChatGPT and Gemini run via cloud API providers, the advantages of onboard LLM processing for privateness, effectivity, and safety are numerous.
GPUs, initially designed to dump and speed up 3D graphics rendering, have grow to be a essential element in processing parallel duties, making them indispensable in gaming and scientific computing. Over time, the GPU’s function expanded into AI and machine studying, courtesy of its means to carry out concurrent operations. Regardless of these developments, the elemental structure of those elements primarily stayed the identical, specializing in general-purpose computing duties and graphics rendering.
The appearance of Groq’s LPU Inference Engine represents a paradigm shift particularly engineered to deal with the distinctive challenges introduced by LLMs. Not like CPUs and GPUs, that are designed for a broad vary of purposes, the LPU is tailored for the computationally intensive and sequential nature of language processing duties. This focus permits the LPU to surpass the restrictions of conventional computing {hardware} when coping with the precise calls for of AI language purposes.
One of many key differentiators of the LPU is its superior compute density and reminiscence bandwidth. The LPU’s design permits it to course of textual content sequences a lot sooner, primarily by lowering the time per phrase calculation and eliminating exterior reminiscence bottlenecks. This can be a essential benefit for LLM purposes, the place shortly producing textual content sequences is paramount.
Not like conventional setups the place CPUs and GPUs depend on exterior RAM for reminiscence, on-die reminiscence is built-in straight into the chip itself, providing considerably lowered latency and better bandwidth for knowledge switch. This structure permits for fast entry to knowledge, essential for the processing effectivity of AI workloads, by eliminating the time-consuming journeys knowledge should make between the processor and separate reminiscence modules. The Groq LPU’s spectacular on-die reminiscence bandwidth of as much as 80 TB/s showcases its means to deal with the immense knowledge necessities of enormous language fashions extra effectively than GPUs, which could boast excessive off-chip reminiscence bandwidth however can’t match the pace and effectivity offered by the on-die method.
Making a processor designed for LLMs addresses a rising want throughout the AI analysis and growth neighborhood for extra specialised {hardware} options. This transfer might doubtlessly catalyze a brand new wave of innovation in AI {hardware}, resulting in extra specialised processing items tailor-made to totally different points of AI and machine studying workloads.
As computing continues to evolve, the introduction of the LPU alongside conventional elements like CPUs and GPUs alerts a brand new part in {hardware} growth—one that’s more and more specialised and optimized for the precise calls for of superior AI purposes.