{kind=link}
By: Terrence Sheflin
Native LLMs have gotten mainstream with websites like HuggingFace selling open sharing of educated LLMs. These LLMs are sometimes very small however nonetheless extraordinarily correct, particularly for domain-specific duties like drugs, finance, legislation, and others. Gemma is a multi-purpose LLM and, whereas small, is aggressive and correct.
Native LLMs even have the benefit of being utterly run inside your personal surroundings. There isn’t a likelihood of information leakage, and P3+ information is ensured to be safe because it by no means leaves the protected community. Just lately Google shared its personal native mannequin: Gemma.
Gemma is a household of light-weight, state-of-the-art open fashions constructed from the identical analysis and know-how used to create the Gemini fashions. Developed by Google DeepMind and different groups throughout Google, Gemma is impressed by Gemini, and the title displays the Latin gemma, that means “valuable stone.” Accompanying our mannequin weights, we’re additionally releasing instruments to assist developer innovation, foster collaboration, and information accountable use of Gemma fashions.
Gemma has been shared on HuggingFace, and can also be obtainable within the in style LLM internet hosting software program Ollama. Utilizing Ollama, Gemma, and Logi Symphony, this text will present find out how to shortly create a chatbot that makes use of RAG so you possibly can work together along with your information, regionally. Not one of the information or questions are ever uncovered to the web or any on-line service exterior of the native community.
Instance
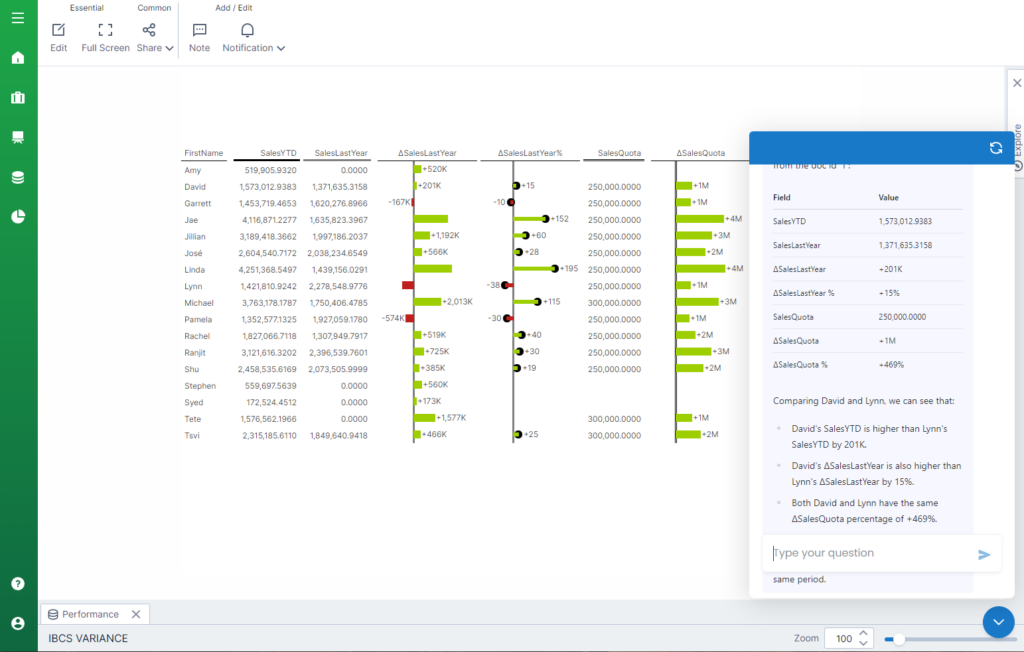
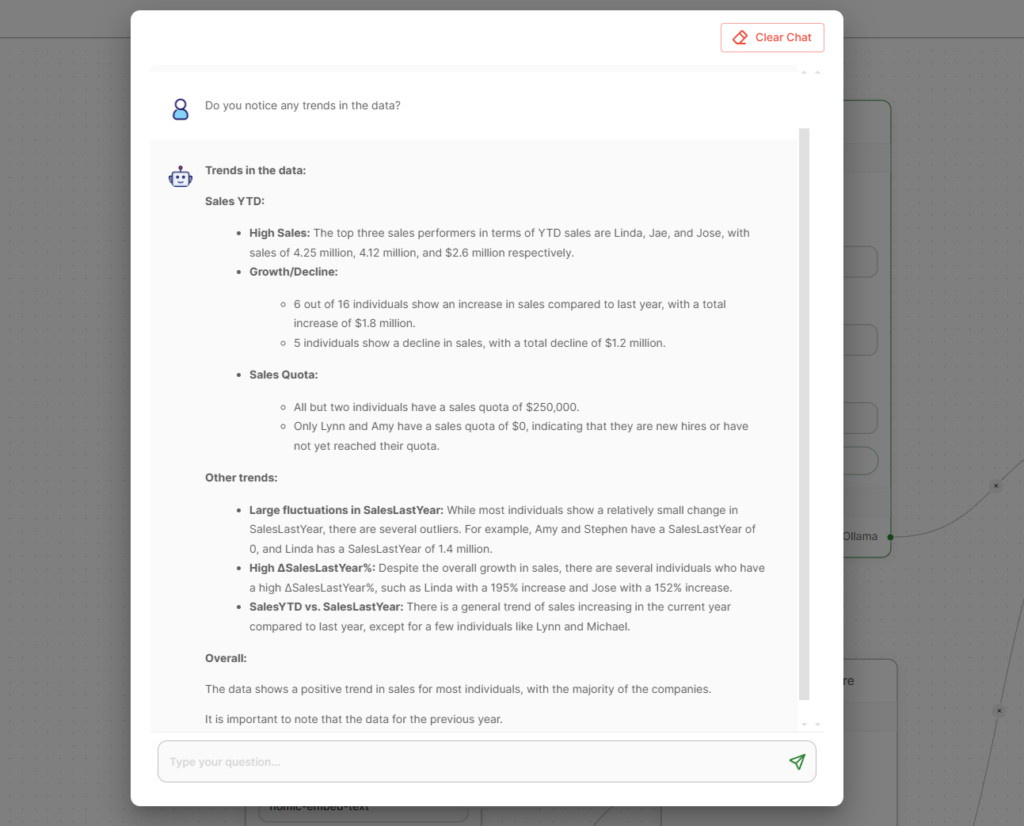
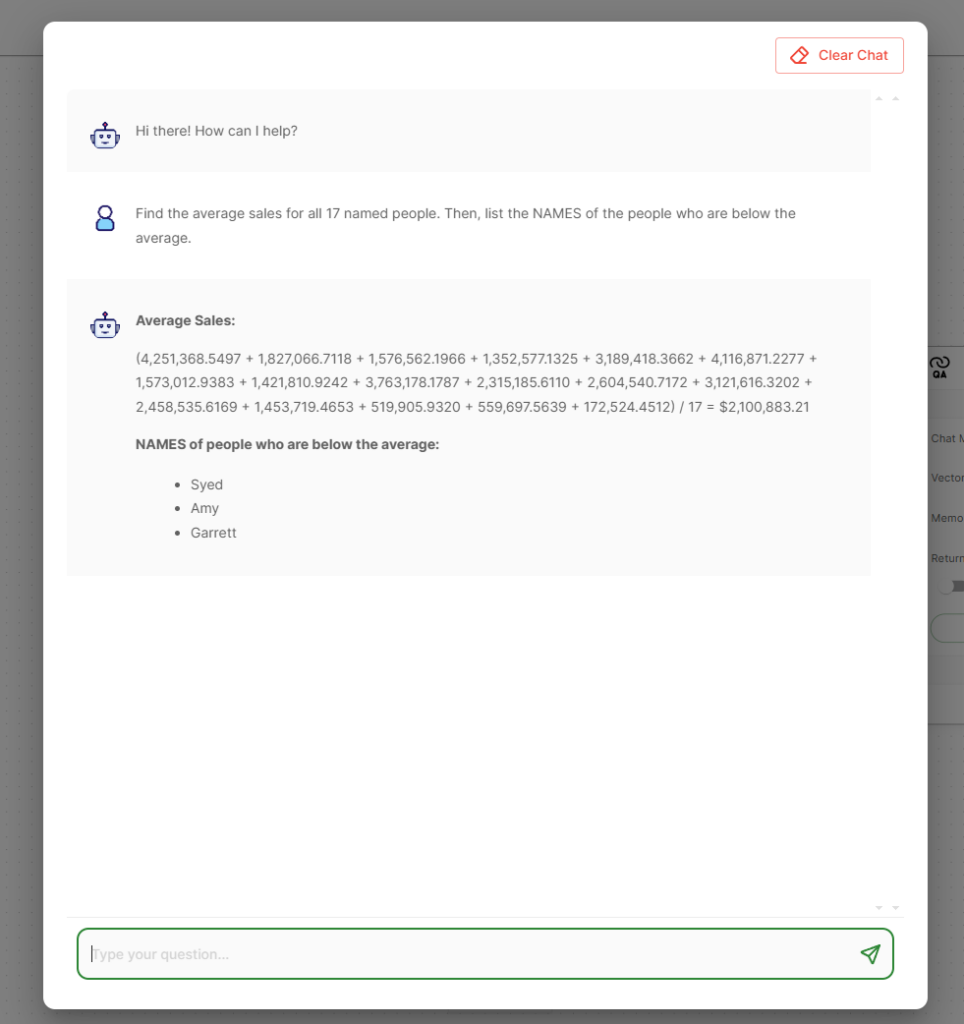
Right here is an instance dashboard in Logi Symphony utilizing Google’s Gemma 2b mannequin on Ollama to reply questions concerning the information.
The entire information and the LLM is totally safe with no data leaving the native cluster.
Setup
Deployment
Step one is to deploy Logi Symphony in Kubernetes as per the set up directions (or use our SaaS providing). As soon as deployed, the subsequent step is so as to add Ollama into the cluster. This may be carried out by way of their current helm chart with the next run throughout the kubectl context:
helm repo add ollama https://otwld.github.io/ollama-helm/
helm repo replace
helm set up ollama ollama/ollama –set ollama.defaultModel=”gemma” –set persistentVolume.enabled=true
Ollama will now be deployed and accessible throughout the cluster as http://olama:11434 and have already got the default gemma mannequin preloaded. For this instance, we additionally use a neighborhood embeddings mannequin. So as to add that, run:
kubectl exec -it — ollama pull nomic-embed-text
The place ollama-pod-name is the title of the Ollama pod deployed above. Deployment is now full!
Information
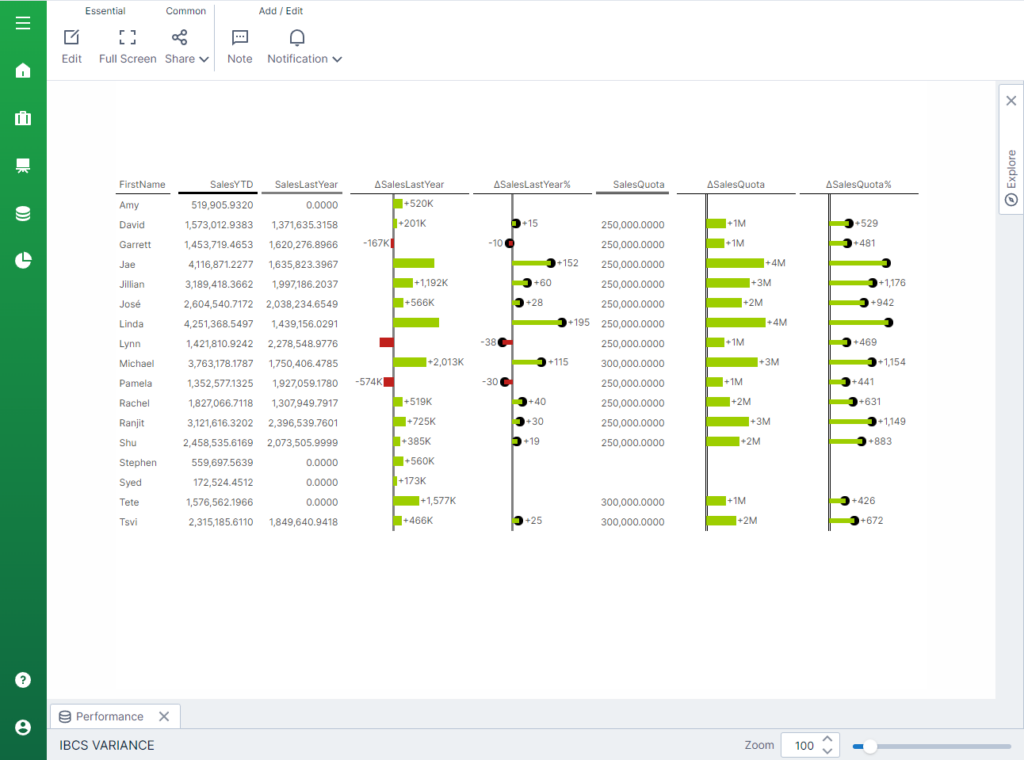
After deployment, create any visible or dashboard with any information you’d like in Logi Symphony, even Excel information. For this instance I used Logi Symphony’s new built-in IBCS Variance management containing gross sales information for this yr and final yr.
Chat move setup
After deployment and dashboard creation, the subsequent step is to create the chat move that can use Gemma to do RAG with information accessible from Logi Symphony. This information might be from any database you will have! So long as Logi Symphony can entry it, Gemma will have the ability to as nicely.
Last chat move
Under is how the chat move ought to take care of being arrange. Every of those nodes could be discovered within the + icon and added.
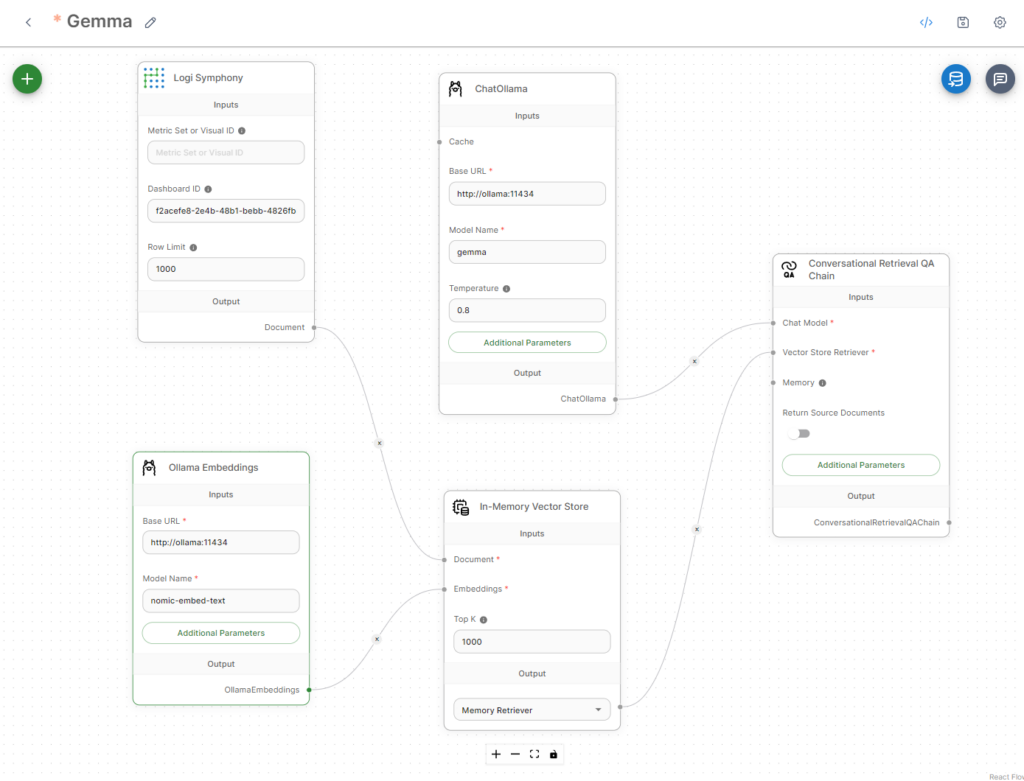
Setup steps
To set this up, begin with a Conversational Retrieval QA Chain. So as to add this, click on the + and increase Chains, then add it.
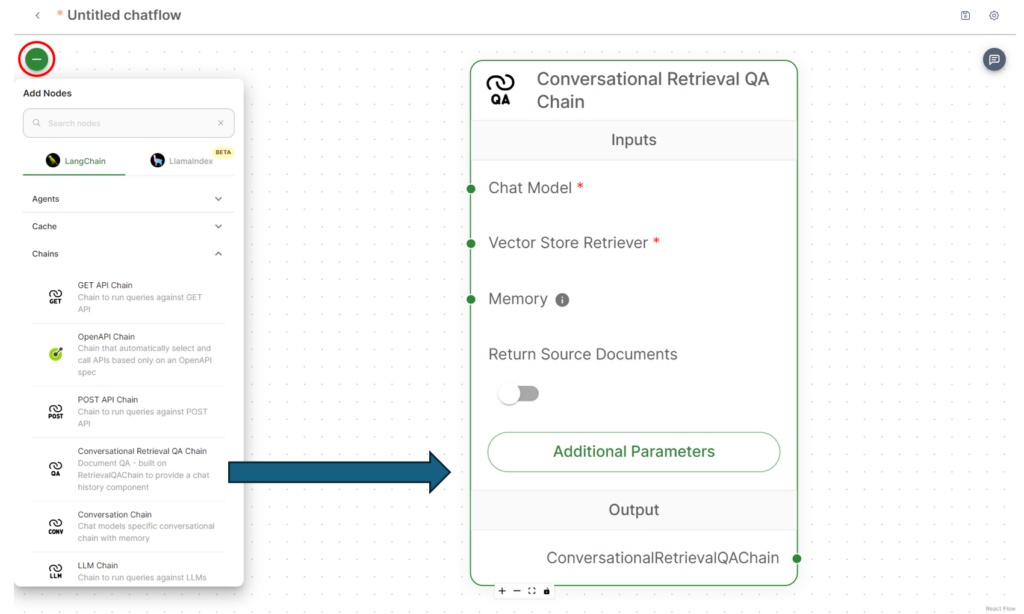
Observe the identical steps so as to add the Chat Ollama from Chat Fashions, In-Reminiscence Vector Retailer from Vector Shops, Logi Symphony from the doc loaders, and at last Ollama Embeddings from embeddings.
Configuration notes
For Chat Ollama, it’s essential to specify the native URL of Ollama. That is usually the native title throughout the Kubernetes cluster. In the event you used the identical helm deployment as above, then it must be http://olama:11434.
As well as, the mannequin have to be specified. If utilizing the default Gemma mannequin, this will merely be gemma. The default gemma mannequin is a 7b-instruct mannequin that has been shrunk by way of quantization. There may be additionally a 2b-instruct mannequin if assets are constrained, however it will likely be much less correct.
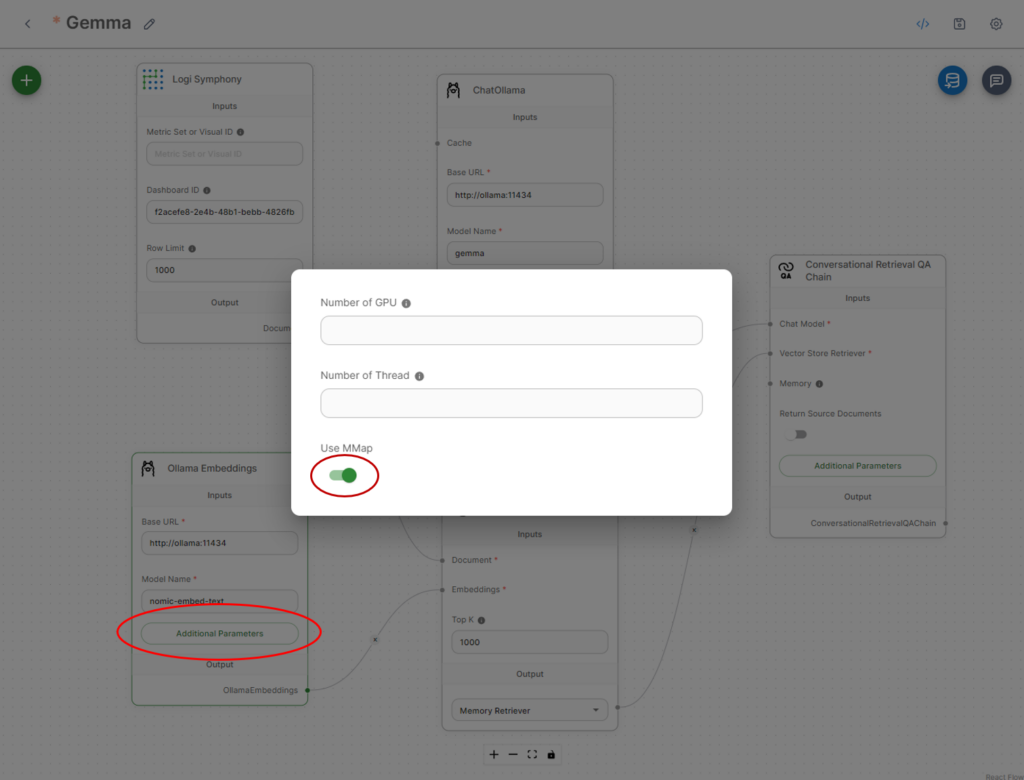
For Ollama Embeddings, it’s essential to specify the identical URL because the chat and the mannequin. For this instance, nomic-embed-text was used, and set up was carried out within the above deployment part.
For embeddings, click on Extra Parameters and guarantee Use MMap is chosen.
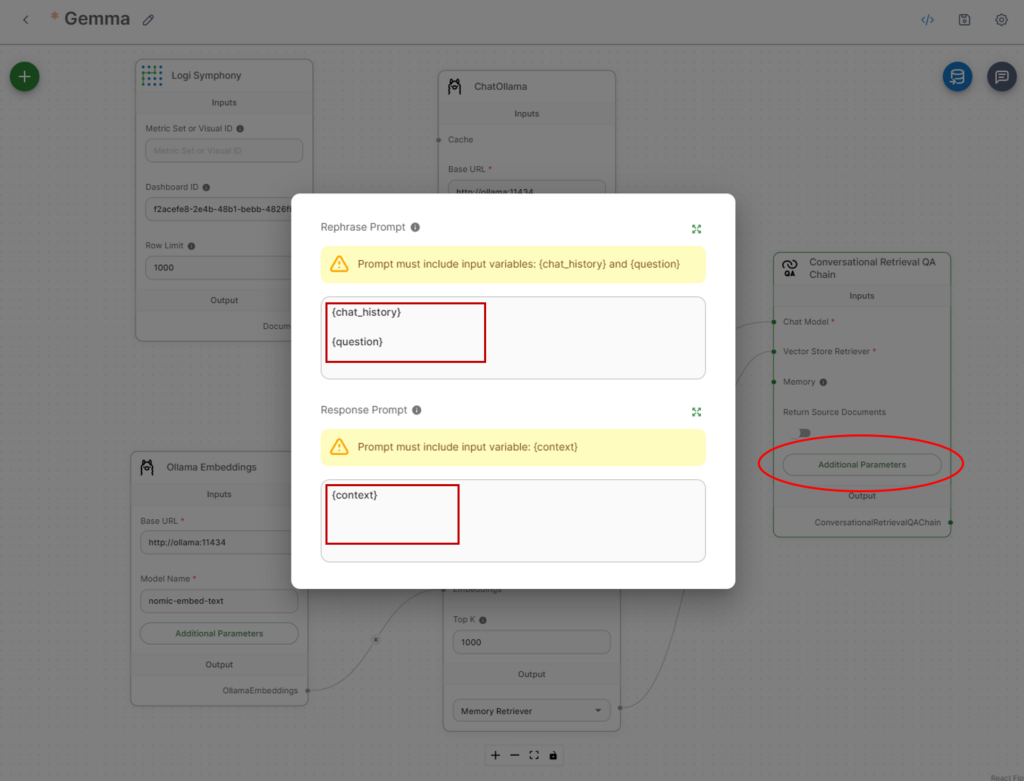
It’s additionally suggested to change the immediate as Gemma appears to do significantly better with a quite simple immediate schema.
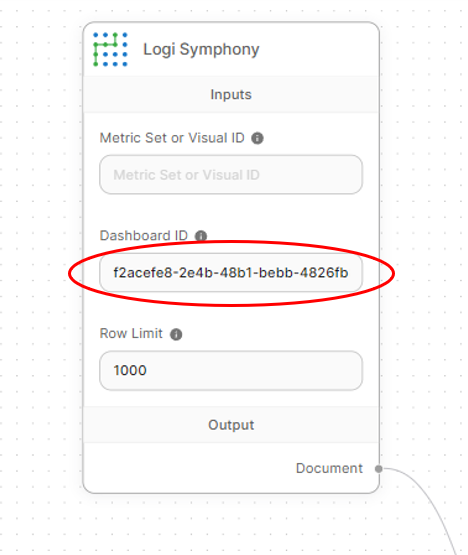
Lastly, set a dashboard or visible ID has been set on the Logi Symphony node in order that information could be retrieved even when it’s not embedded. That is an optionally available step, however it permits utilizing the chatbot when it’s not embedded inside a dashboard.
Ask it questions!
Now that every part is setup, you possibly can ask questions concerning the information proper in Logi AI.
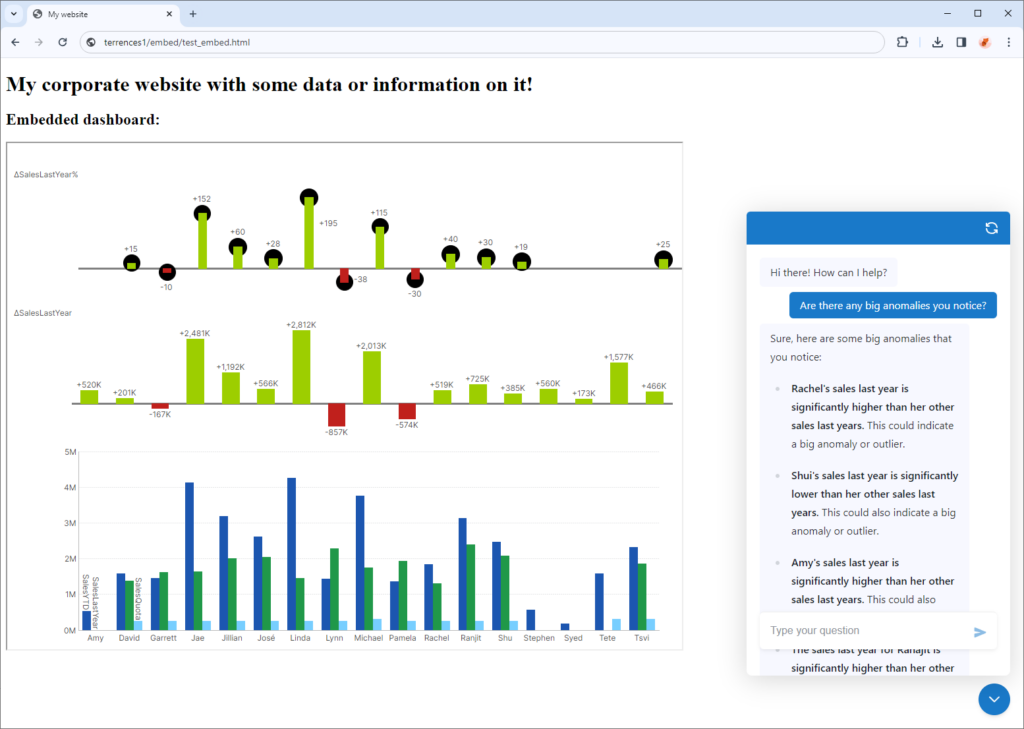
Embed it
The chatbot doesn’t need to be accessed solely inside Logi AI, it can be accessed proper on the dashboard for anybody to make use of it, and even utterly individually when embedded inside a buyer’s portal.